
.png)

Cuando una empresa decide automatizar ERP con un LLM agéntico, la idea inicial parece sencilla: el modelo lee las facturas, las procesa y las registra. En los pilotos, ese proceso funciona bien. El consumo de tokens parece manejable. El costo proyectado parece razonable.
El problema aparece en producción real, cuando el volumen es alto y los flujos de trabajo son completos. Porque procesar una factura de subcontratista no es solo leerla. Es verificar que el proveedor existe en el maestro del ERP. Comprobar que el código de costo es válido para ese proyecto. Verificar que el monto no supera el saldo del subcontrato. Detectar si ya fue procesada. Determinar la ruta de aprobación según el monto. Registrar el resultado con trazabilidad.
Cada uno de esos pasos, en un sistema basado en LLM puro, implica que el modelo razone sobre la respuesta, lo que significa tokens. No porque el modelo sea ineficiente, sino porque esa es la única forma en que un LLM puede operar: generando texto token a token.

La metodología fue específica: no medimos el consumo en demos ni en pilotos controlados. Medimos el consumo en producción real, con el volumen completo de cada empresa, durante cuatro meses consecutivos. Esto nos permitió capturar el comportamiento real del sistema bajo las condiciones en las que las empresas operan, no bajo las condiciones ideales en las que se venden.
Los resultados fueron consistentes en los 63 casos analizados. Lo que varía entre empresas es la magnitud del problema, no la naturaleza del mismo.


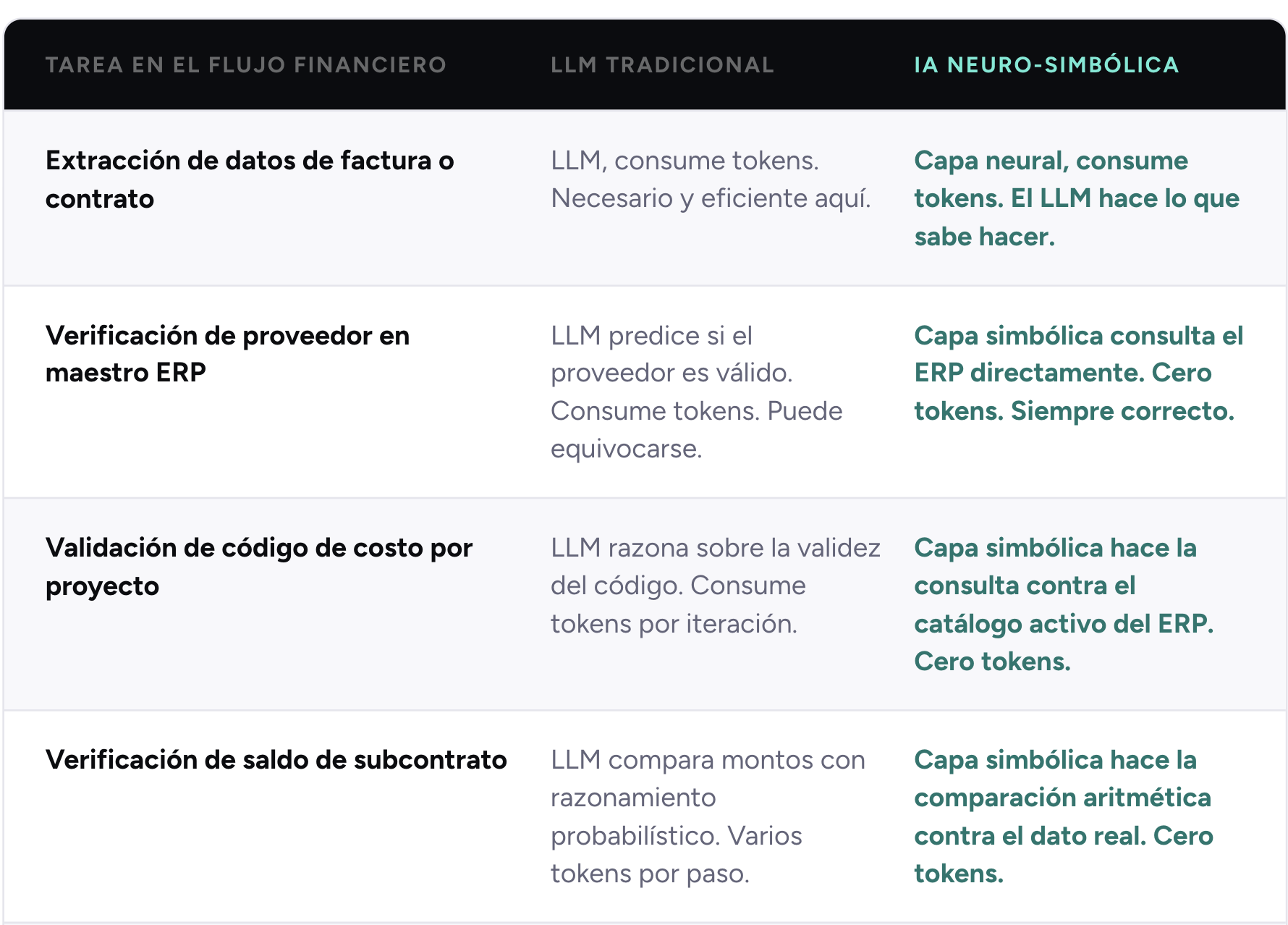
Este dato cambia completamente el análisis de costos. La intuición de muchos equipos es que el costo principal de un LLM en automatización financiera viene de leer los documentos, porque esa es la parte que requiere comprensión de lenguaje natural. Un contrato en PDF, una factura escaneada, una orden de cambio con texto ambiguo: esos documentos sí requieren un modelo de lenguaje para ser interpretados correctamente.
Pero la investigación muestra que leer el documento es solo el 27% del consumo. El 73% viene de lo que pasa después: todo el proceso de verificar, validar, comparar y decidir. Y ese 73% no requiere razonamiento de lenguaje. Requiere consultar bases de datos, aplicar reglas y comparar valores. Exactamente lo que hace la capa simbólica, sin tokens.


La diferencia con un LLM es fundamental. Cuando un LLM necesita verificar si un código de costo es válido para un proyecto específico, genera una respuesta a esa pregunta basándose en patrones que aprendió durante el entrenamiento. Eso consume tokens porque genera texto. Y puede equivocarse, porque está prediciendo la respuesta más probable, no consultando la fuente de verdad.
Cuando la capa simbólica verifica el mismo dato, hace una consulta directa a la base de datos del ERP. El código de costo existe o no existe. El saldo es suficiente o no lo es. El proveedor está activo o no lo está. No hay predicción, no hay generación de texto, no hay tokens consumidos. Y el resultado es determinístico: siempre correcto, siempre trazable, siempre auditable.
Esta es la razón por la que el ERP pasivo implementado sobre arquitectura neuro-simbólica puede reducir trabajo manual en finanzas B2B de forma sostenible a medida que el volumen crece. El costo de tokens no escala con la complejidad del flujo de validación porque esa complejidad se maneja en la capa simbólica, no en el LLM.

Cuando una empresa evalúa si tiene sentido económico automatizar ERP o reducir la carga operativa de su equipo financiero con IA, el análisis de costo tiene que incluir no solo el costo del piloto, sino el costo en producción a escala real. Y ahí es donde la arquitectura hace toda la diferencia.
Una empresa de construcción que procesa 4,000 facturas de subcontratistas al mes con un LLM agéntico no está pagando solo por la extracción de datos. Está pagando por cada verificación, cada comparación, cada iteración de razonamiento. En nuestros datos, el costo mensual de tokens en ese escenario resultó ser entre tres y cinco veces mayor que lo que el equipo proyectó basándose en el piloto.
La misma empresa con ERP pasivo sobre arquitectura neuro-simbólica paga tokens solo por la extracción, que es el 27% del flujo. El 73% restante, todo el proceso de validación, se ejecuta en la capa simbólica a costo fijo. El costo total es predecible, controlable y no se multiplica cuando el volumen crece.

La implementación funciona en cuatro pasos que no requieren interrumpir la operación actual. Primero, el agente se conecta al ERP existente, ya sea SAP, Oracle, CMiC, Viewpoint, Sage o NetSuite, sin modificar su configuración. Segundo, la capa simbólica se configura con las reglas del negocio de la empresa: catálogo de cuentas, maestro de proveedores, límites de aprobación, estructuras de proyectos activos. Tercero, el agente comienza a procesar el volumen de documentos de forma autónoma, ejecutando la validación en la capa simbólica y usando el LLM solo para la extracción de documentos no estructurados. Cuarto, el equipo financiero recibe solo las excepciones que requieren criterio humano, con una explicación clara de por qué el sistema no pudo resolverlas automáticamente.
El efecto sobre el costo de tokens es inmediato y medible. Desde el primer mes de producción real, el consumo de tokens corresponde únicamente a la extracción de documentos, que es proporcional al número de documentos nuevos. La validación, que en un sistema LLM puro representaría el 73% del costo, no genera ningún gasto de tokens adicional.
¿Qué es la IA neuro-simbólica y por qué consume menos tokens que un LLM?
La IA neuro-simbólica combina una capa neural, que usa un LLM para entender documentos no estructurados, con una capa simbólica, que aplica reglas explícitas para validar y decidir sin llamadas adicionales al modelo. Como la mayor parte del proceso financiero, verificar proveedores, validar códigos de costo, detectar duplicados, consiste en aplicar reglas y consultar datos, la capa simbólica lo resuelve sin consumir tokens. En flujos financieros B2B, esto representa una reducción del 85% en el consumo de tokens respecto a un sistema basado únicamente en LLM agéntico.
¿Cuánto puede ahorrar en tokens una empresa B2B al pasar de un LLM tradicional a IA neuro-simbólica para automatizar ERP?
Según los datos de Pantera Research con 63 empresas en producción real, el ahorro en tokens al pasar de un LLM agéntico a IA neuro-simbólica para los mismos flujos de trabajo financieros es del 80% al 88% por transacción procesada. En términos de costo mensual, una empresa que procesa 3,000 facturas al mes puede pasar de un gasto de tokens de USD 8,000 a USD 12,000 mensuales con LLM agéntico a un gasto de USD 1,200 a USD 2,000 mensuales con IA neuro-simbólica para el mismo volumen.
¿Qué es el ERP pasivo y cómo usa la IA neuro-simbólica para reducir trabajo manual en finanzas B2B?
El ERP pasivo es una arquitectura donde un agente inteligente, construido sobre IA neuro-simbólica, se conecta al ERP existente de la empresa y opera los procesos financieros rutinarios de forma automática. Reduce el trabajo manual en finanzas B2B porque automatiza la captura, validación y registro de transacciones sin que el equipo cambie su forma de trabajar ni el ERP sea reemplazado. El ahorro en tokens se debe a que la validación, que representa el 73% del proceso, se ejecuta en la capa simbólica sin consumo de tokens del LLM.


.png)

.png)
.png)
.png)
Con la IA Neuro Simbolica el problema de depender de los cambios que haga tu provedor de ERP se acabó.
